
Table of Contents
In the previous post, I presented a simple SparkSQL app & executed the app directly from the IDE & later by submitting the app via spark-submit script. Spark supports multiple modes of execution aka cluster types. In order to better understand cluster types, we first have to take a quick look at Spark’s core runtime components.
Spark components
Following is a high level overview of major components involved in any Spark application.
Driver
Driver program initiates & monitors the Spark application. There can only be one driver per Spark application. Driver program is responsible for requesting memory, creating stages & tasks, sending tasks to executors etc.
Executors
Executors are standlone JVM process that accept tasks from driver program & execute those tasks. Spark applications can have multiple executors & each executors can have multiple task slots which are nothing but threads that are in correspondence with number of cores available on the machine in which executor is running.
Master
Master process acts as cluster manager. It instructs Spark worker process to launch driver & executors. Client application submits Spark application to master for processing & interacts with it for application status. Spark application can have only one master.
Worker
Workers are another layer of abstraction between master & driver program & executors. Workers initiate driver & spin up executors. Spark application can have multiple workers.
Cluster Type
Below is a quick overview of various cluster types available for running Spark applications.
Standalone Cluster Mode
As the name suggests, its a standalone cluster with only spark specific components. It doesn’t have any dependencies on hadoop components and Spark driver acts as cluster manager.
YARN Cluster
YARN is hadoop resource manager. If you have at your disposal a hadoop cluster then you can configure your Spark application to run against that cluster & leverage YARN as resource manager. You can read more about running Spark on YARN here.
Mesos Cluster
Mesos is another fault-tolerant distributed system. When running Spark against Mesos cluster, Mesos replaces Spark master as the cluster manager. Running Spark against Mesos cluster is documented in detail here.
Local Mode
Spark local mode is special case of standlaone cluster mode in a way that the _master & _worker run on same machine. These cluster types are easy to setup & good for development & testing purpose. In this post, I am going to show how to configure standalone cluster mode in local machine & run Spark application against it.
Standalone Local Cluster Mode
As mentioned before, this post is directed towards setting up & running a simple application in local cluster mode. Running the app in local cluster mode involves:
- Starting the master
- Starting the worker & registering the worker against master
- Submitting the application against the master
I am assuming that you have followed the previous post & configured Spark in your local machine. And you also have the sample SparkSQL program from previous post up & running in your machine. Running $SPARK_HOME from command line should return : /Users/username/bin/spark
Starting Master & Worker
First we will start the Spark master instance by running the following command:
~ $SPARK_HOME/sbin/start-master.sh
If running this command throws the following error:
Exception in thread "main" java.net.BindException: Can't assign requested address: Service 'sparkMaster' failed after 16 retries! Consider explicitly setting the appropriate port for the service 'sparkMaster' (for example spark.ui.port for SparkUI) to an available port$
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at io.netty.channel.socket.nio.NioServerSocketChannel.doBind(NioServerSocketChannel.java:125)
at io.netty.channel.AbstractChannel$AbstractUnsafe.bind(AbstractChannel.java:485)
at io.netty.channel.DefaultChannelPipeline$HeadContext.bind(DefaultChannelPipeline.java:1089)
at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:430)
at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:415)
at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:903)
at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:198)
at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:348)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:357)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:745)
then try running the command by explicity passing the hostname value i.e.
~ $SPARK_HOME/sbin/start-master.sh --host 127.0.0.1
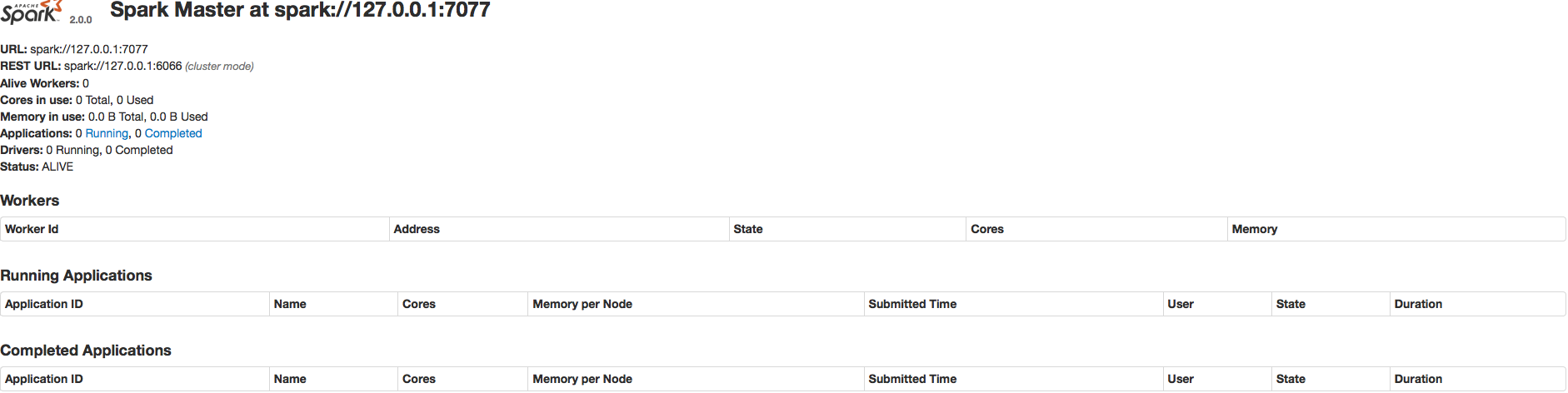
This should start the master node. Once master process is up & running, Spark also starts the Spark Master UI which is accessible at : http://127.0.0.1:8080. 8080 is the default port. If in case this URL is not working for you then check the log file for actual URL. Below is the screenshot of Spark Master UI. Since we have not started worker & neither we have submitted any application, then UI is mostly blank.
It’s important to remember that SparkUI is different from Spark Master UI. Default SparkUI is accessible on port 4040 whereas Master Ui is available at 8080.
Once master node is started then run the worker(slave) process via following command:
➜ ~ $SPARK_HOME/sbin/start-slave.sh spark://127.0.0.1:7077 --host 127.0.0.1
starting org.apache.spark.deploy.worker.Worker, logging to ....
Once worker process is up & running then refresh the SparkUI & you will notice that worker related information.

This finishes the setup. Next we will re-use our previously created SparkSQL application & submit it for processing in our locally running cluster.
Running the App
In the previous post, we implemented the simple SparkSQL program. We will re-use the same application with one minor change in code.
def main(args: Array[String]) {
// setup SparkSession instance
val spark = SparkSession
.builder()
.appName("SparkSQL For Csv")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// Read csv file
val df = spark.read.option("header","true").option("delimiter",",").csv("/path/to/file/Person_csv.csv")
// Optional. Calling printSchema prints the inferred schema. See output below.
df.printSchema()
// Registers the DataFrame in form of view
df.createOrReplaceTempView("person")
// Actual SparkSQL query
val sqlPersonDF = spark.sql(
"""
|SELECT
| PersonID AS PersonKey,
| 'XYZ' AS IdentifierName,
| PersonIndex AS Extension,
| 'A' AS Status
| FROM person
| WHERE
| PersonID IS NOT NULL AND PersonIndex IS NOT NULL
| UNION
| SELECT
| PersonID AS PersonKey,
| 'ABC' AS IdentifierName,
| RecordNumber AS Extension,
| 'A' AS RecordStatus
| FROM person
| WHERE
| PersonID IS NOT NULL AND RecordNumber IS NOT NULL
| UNION
| SELECT
| PersonID AS PersonKey,
| 'MNO' AS IdentifierName,
| SSN AS Extension,
| 'A' AS RecordStatus
| FROM person
| WHERE
| PersonID IS NOT NULL AND SSN IS NOT NULL
""".stripMargin)
// Print the result. See output below
sqlPersonDF.show(50)
}
Remove this line .master(“local[*]”) from the above code & re-build the jar. Steps for building the jar was covered in the previous post. Setting master to local[], causes the Spark app to run in local mode i.e. the spark master & the worker are all running inside the client application JVM. Instead we are going to submit our application using spark-submit script against the master which we explicitly started.
spark-submit
Assuming you have successfully built the jar, then run the following command. It submits our application by explicitly telling it to run against locally running master process. Once master recieves the application, it starts the worker which in-turn starts driver & executor program.
$SPARK_HOME/bin/spark-submit --master spark://127.0.0.1:7077 --class SparkSqlRunner SparkForDummies.jar "/Users/username/vm_shared/Patient_csv.csv"
I ran into some hostname related issues when running the above command in my local machine. In order to resolve it, I had to do the following: run the hostname command take the value & add it against 127.0.0.1 in /etc/hosts file i.e. 127.0.0.1 {hostname value}
Running the above command will generate similar output as we saw in previous post. Once the application is submitted, we can also check its status in Spark Master UI. Screenshot:
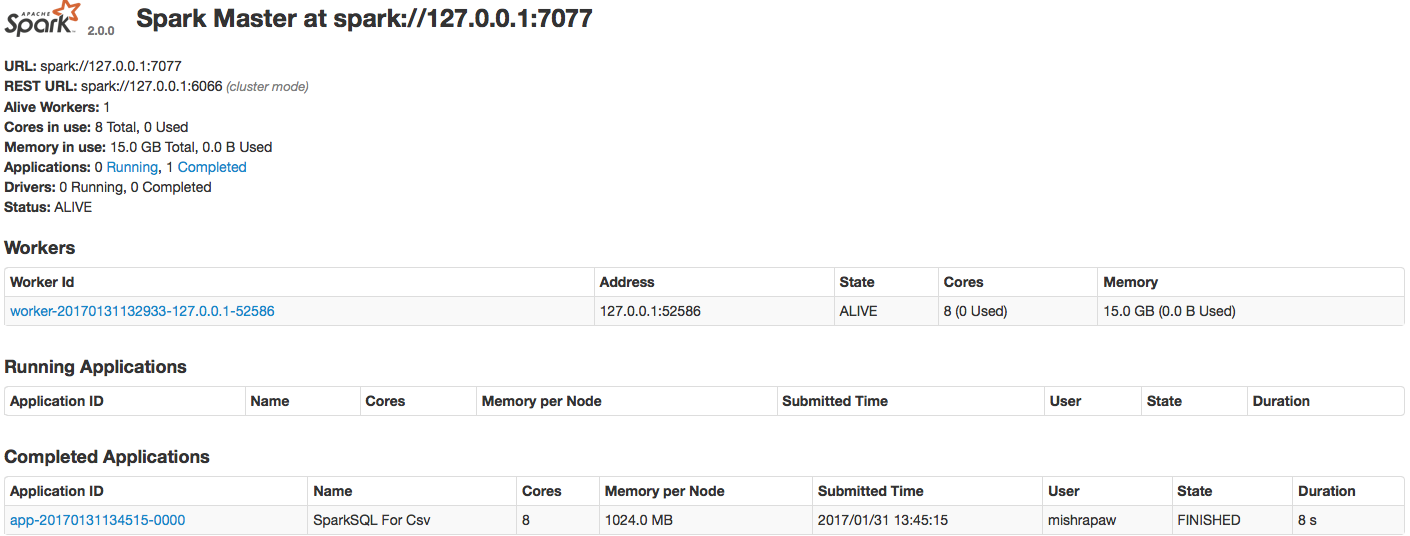
Running Spark in local mode(directly from IDE or via standalone cluster mode) is really helpful in expediting the development process. There is lot more to Spark like how to provide schema, debugging running app & performance considerations. All this & more in upcoming posts. Till then enjoy!!