
Table of Contents
If we ignore the complexities of running spark applications then getting up-to speed with spark programming api is relatively straight forward. However like any other programming api, spark too contains some elements that aren’t that obvious to figure out. In this post, I will share some not so obvious things about spark programming api.
Reduce Logging
If you have ever executed spark application, then you must have witnessed the massive amount of console logging spark generates. Most of it is sparks internal debug level logging. If you too have add log statements in your code then good luck looking for your application specific messages in the output logs. The fix for reducing spark logging is easy. Just set the log level to ERROR on the spark context object.
val spark = SparkSession
.builder()
.appName("Spark for blog")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
DataFrame From Case Classes
Say you have collection of case classes and you want to convert the collection into DataFrame then you will have to manually define the schema of the DataFrame using StructType. Consider the following example:
import scala.collection.JavaConverters._
case class Patient(patientId: Integer, name: String)
def main(args: Array[String]): Unit = {
implicit val spark = SparkSession
.builder()
.appName("Spark For Blog")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
val df = createPatients(
Patient(1, "abc"),
Patient(2, "def")
)
df.show()
df.printSchema()
spark.close()
}
def createPatients(patients: Patient*)(implicit spark: SparkSession): DataSet[Row] = {
val schema = StructType(
Seq(StructField("patientId", IntegerType, nullable = true),
StructField("name", StringType, nullable = true)))
val rows = mutable.ListBuffer(patients.map(f => Row(f.patientId, f.name)): _*)
spark.createDataFrame(rows.asJava, schema)
}
Output
+---------+----+
|patientId|name|
+---------+----+
| 1| abc|
| 2| def|
+---------+----+
root
|-- patientId: integer (nullable = true)
|-- name: string (nullable = true)
Our data model was simple with just two columns. Imagine having dozens of columns with varying data types. Manually creating & maintaining the schema definition is tedious. Luckily there a much simpler way of converting sequence of case classes into data frame.
import scala.collection.JavaConverters._
case class Patient(patientId: Integer, name: String)
def main(args: Array[String]): Unit = {
implicit val spark = SparkSession
.builder()
.appName("Spark For Blog")
.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
val df = DataFrame(
Patient(1, "abc"),
Patient(2, "def")
)
df.show()
df.printSchema()
spark.close()
}
def DataFrame[A : Encoder](data: A*)(implicit spark: SparkSession): DataFrame = {
import spark.implicits._
data.toDF()
}
Broadcast Join
When working with data frames, performing joins across multiple data frames is a standard operation. However, joins are expensive operation and it causes shuffle i.e. movement of data across executors. Just like any other relational database engine, sparks catalyst optimizer too tries its best to optimize the sql operations. It uses runtime heuristics to come up with logical plan followed by optimized logical plan and finally actual physical plan. It’s always best to leave query optimization work task with the underlying execution engine but in some cases we can provide additional hints to the optimizer. Using broadcast is one such mechanism.
Consider the following dataframes and their schemas:
- encounters: 150000 records
- patients: 2000 records
root
|-- encounter_id: string (nullable = true)
|-- patient_id: string (nullable = true)
|-- dateof_birth: string (nullable = true)
|-- gender: string (nullable = true)
root
|-- source: string (nullable = true)
|-- patient_id: string (nullable = true)
Following spark code performs join between the two datasets using standard inner join.
val encounters = spark.read.option("header", "true").option("delimiter", "|").csv("~/TrainerData/encounters.txt")
val patients = spark.read.option("header", "true").option("delimiter", "|").csv("~/TrainerData/patients.txt")
val ids = encounters.join(patients, encounters("patient_id") === patients("patient_id"), "inner").select(encounters("encounter_id"))
ids.show(false)
When executed, spark performed the join using SortMergeJoin mechanism. See the screenshot below:
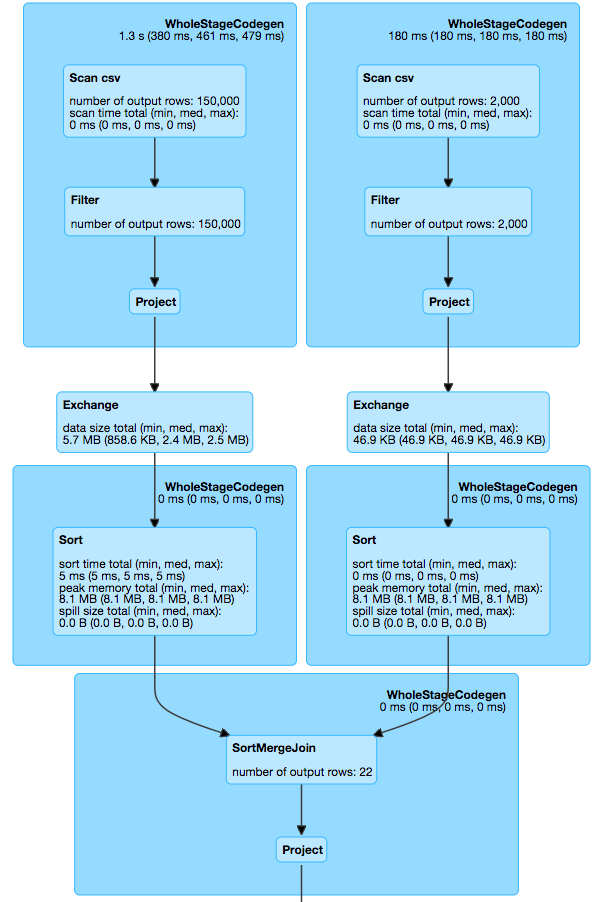
As mentioned before, spark optimizer will come up with most optimal way of performing the join. But if we look at our DataSet, then the patients DataFrame is really small in size when compared with encounters. And in such cases, we can utilize the newly added broadcast hash join technique. Only modification required in the query is to wrap the smaller DataSet in broadcast method call.
import org.apache.spark.sql.functions._
val ids = encounters.join(broadcast(patients), encounters("patient_id") === patients("patient_id"), "inner")
.select(encounters("encounter_id"))
ids.show(false)
With broadcast, the generated plan looks something like below:
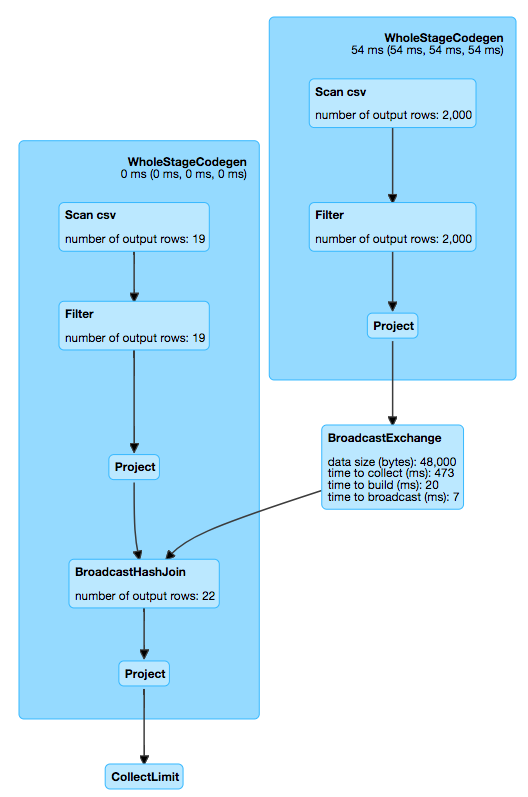
Some important things to keep in mind when deciding to use broadcast joins:
- If you do not want spark to ever use broadcast hash join then you can set autoBroadcastJoinThreshold to -1. E.g. spark.sqlContext.sql(“SET spark.sql.autoBroadcastJoinThreshold = -1”)
- Spark optimizer itself can determine whether to use broadcast join or not. You can explicitly specify broadcast when you are absolutely certain about your datasets size & data quality.
- With broadcast the data has to be first shipped back to driver & then broadcasted to all executors. If the amount of data being broadcasted is large then it can cause out of memory exception.
DataFrame to DataSet
DataSet are basically strongly typed dataframes. With the help of case classes, we can convert a DataFrame into a DataSet. Consider the below code snippet in which I convert a DataFrame(read from csv file) into a strongly typed DataSet.
case class Diagnoses(poa: Boolean, encounterId: String, codeSystem: String, code: String, sequence: Int, source: String)
val diagnoses = spark.read.option("header", "true").option("delimiter", "|").csv("~/dev/TrainerData/diagnoses.txt")
val DataSet = diagnoses.select(
diagnoses("present_on_admission").as("poa"),
diagnoses("encounter_id").cast(IntegerType).as("encounterId"),
diagnoses("code_system").as("codeSystem"),
diagnoses("code").as("code"),
diagnoses("sequence").cast(IntegerType).as("sequence"),
diagnoses("source").as("source")
).as[Diagnoses]
Idea here is to define a case class & ensure that the output of select on DataFrame matches exactly with case class definition. With one-on-one matching its relatively simple. In the example below, I am casting result of a group by operation on a DataFrame into a strongly typed DataSet.
// first declare the case class structure
case class Code(code: String, codeSystem: String, sequence: String)
case class EncounterCodes(encounter_id: String, codes: Option[Seq[Code]])
val diagnoses = spark.read.option("header", "true").option("delimiter", "|").csv("~/dev/TrainerData/diagnoses.txt")
import org.apache.spark.sql.functions._
val groupedCodes = diagnoses.groupBy(diagnoses("encounter_id"))
.agg(collect_list(struct(diagnoses("code").as("code"), diagnoses("code_system").as("codeSystem"), diagnoses("sequence").as("sequence"))).as("codes")).as[EncounterCodes]
groupedCodes.show(false)
The above code outputs the following:
+------------+---------------------------------------------------------------------------------------+
|encounter_id|codes |
+------------+---------------------------------------------------------------------------------------+
|3662 |[[Z91.81,ICD-10-CM,4], [J44.0,ICD-10-CM,2], [Z51.5,ICD-10-CM,7], [Z91.81,ICD-10-CM,10]]|
|4471 |[[Z51.5,ICD-10-CM,5]] |
|7693 |[[J44.0,ICD-10-CM,6], [Z51.5,ICD-10-CM,10], [Z79.899,ICD-10-CM,1]] |
|4908 |[[Z51.5,ICD-10-CM,2], [Z99.11,ICD-10-CM,5]] |
+------------+---------------------------------------------------------------------------------------+